
Ще зовсім недавно комп’ютери були абсолютно сліпими. Для машини будь-яке цифрове зображення було не котом, автомобілем чи людським обличчям, а просто безкінечною таблицею з чисел-пікселів. Навчити залізо «бачити» реальний світ вважалося майже нездійсненною задачею. Об’єкти довкола нас постійно змінюють ракурс, освітлення, масштаби, ховаються в тіні чи перекриваються іншими речами. Звичайних наборів із кількох тисяч фотографій, які були у вчених, катастрофічно не вистачало, щоб пояснити машині все це візуальне різноманіття.
Творці перших успішних систем штучного інтелекту згодом прямо писали: без мільйонів прикладів для навчання нічого не вийде. Але таких масштабних баз даних у світі просто не існувало.
У ті часи програмісти намагалися контролювати все вручну. Вони буквально на пальцях прописували в коді правила: на що саме комп’ютеру дивитися. Програму змушували шукати на картинці різкі перепади кольору, контури, кути чи геометричні фігури, сподіваючись, що з цих шматочків зліпиться правильний образ. Це був «кам’яний вік» комп’ютерного зору. Машина могла порахувати математичну статистику ліній на фото, але абсолютно не розуміла змісту сцени.
Вся індустрія трималася на переконанні, що людина спочатку повинна сама придумати, які деталі на картинці є важливими, і лише потім дати комп’ютеру команду їх шукати. Прорив 2012 року зруйнував цю логіку вщент.
Перцептрон і перша зима штучного інтелекту
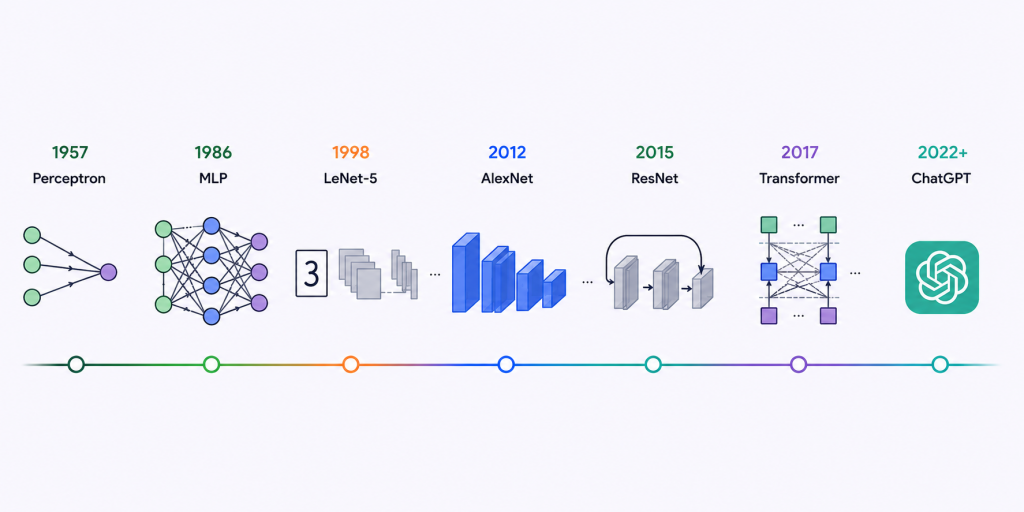
Взагалі, вся ця історія почалася ще наприкінці 1950-х років. У 1957 році американський вчений Френк Розенблатт придумав перцептрон – першу математичну модель штучної нейромережі. Вже за рік він разом із колегами зібрав під цю ідею величезну аналогову машину з купою дротів та перемикачів. Пристрій мав три типи вузлів, які імітували біологічні процеси: «відчуття», «асоціація» та «реакція». Це була перша спроба скопіювати роботу людського мозку в металі.
Головним досягненням була сама ідея, а не точність пристрою. Під час перших демонстрацій ця громіздка машина після кількох десятків спроб навчилася відрізнятися картки з помітками ліворуч від карток із помітками праворуч. Для публіки це виглядало як чиста наукова фантастика. Машина не просто виконувала жорсткий алгоритм, написаний людиною – вона сама покращувала свої результати на основі помилок. Саме тоді індустрія отримала свою найважливішу ідею: інтелект не потрібно програмувати до дрібниць, його можна просто навчити, як дитину.
Але перша модель мала серйозну математичну межу. Нейромережа Розенблатта була «одношаровою» – вона могла вирішувати лише найпримітивніші логічні задачі. Невдовзі інші відомі вчені випустили книгу, де детально і тверезо розписали всі обмеження цієї системи.
Проблема була в тому, що на той момент ніхто у світі не знав, як створювати і, головне, ефективно тренувати складніші, багатошарові нейромережі. В результаті корисне твердження «перша модель надто проста» у сприйнятті суспільства перетворилося на жорсткий вирок: «нейромережі – це глухий кут».
До початку 1970-х років наукова спільнота майже повністю закинула цей напрям. Інтерес згас, фінансування проектів припинилося. Цей період в історії комп’ютерних наук офіційно назвали «зимою штучного інтелекту». Перша модель не була помилковою – вона просто з’явилася занадто рано. Ідея випередила свій час, адже технологій та потужностей для її масштабування тоді ще не існувало.
Багатошарові мережі та метод зворотного поширення помилки
Рішення напрошувалося саме собою: якщо один прошарок штучних нейронів здатний провести лише просту роздільну лінію, потрібно нашарувати їх один на одного. Так система зможе розуміти складніші, заплутані зв’язки. Проте сам факт створення багатошарової мережі не вирішував головного – як змусити її вчитися? Як зрозуміти, який саме з тисячі віртуальних нейронів помилився під час тесту?
Перелом відбувся у 1986 році завдяки групі вчених, серед яких був і Джеффрі Гінтон – людина, яку сьогодні називають «хрещеним батьком сучасного ШІ». Вони описали алгоритм зворотного поширення помилки (backpropagation). Працювало це так: мережа робила прогноз, аналізувала свою помилку на виході, а потім цей сигнал «котився» назад по всіх шарах мережі, автоматично підкручуючи налаштування кожного нейрона.
Найважливішим тут була нова обіцянка: складна нейромережа тепер могла самостійно, без допомоги людини, знаходити приховані закономірності в даних.
Технологія знову отримала шанс на життя, але реального комерційного застосування все ще не було. Навчити крихітну модель на папері – це одне, а запустити важку систему на мільйонах реальних зображень – зовсім інша історія. Нейромережам банально бракувало двох речей: гігантських масивів даних для прикладів та колосальної обчислювальної потужності. Алгоритм дав машинам здатність вчитися, але світ ще не підготував для них пального.
Наочний приклад: як мережі вчилися бачити
Першим серйозним і практичним «оком» штучного інтелекту стала згорткова нейромережа LeNet-5, створена наприкінці 1990-х років командою під керівництвом Яна Лекуна. Вони змусили модель розпізнавати рукописні цифри, і саме тут з’явилися принципи, на яких тримається весь сучасний комп’ютерний зір.
Замість того щоб аналізувати всю велику картинку цілком, мережу навчили дивитися на неї через маленькі віртуальні «вікна», які послідовно ковзали по зображенню. Перші шари нейромережі помічали найпростіші речі – штрихи, лінії та контрастні краї. Наступні шари склеювали ці лінії докупи, виділяючи вже складніші елементи: чіткі силуети, групування тіней чи специфічну текстуру поверхні. Фінальні шари збирали ці фрагменти в цілісну картину й видавали остаточний результат – наприклад, що на фото зображена кішка.
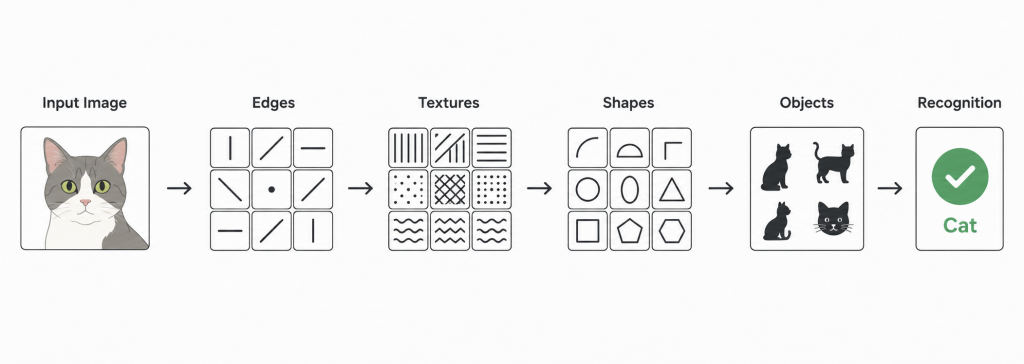
Це довело, що візуальні ознаки предметів не потрібно вигадувати з голови – комп’ютер може вивчити їх сам, просто дивлячись на правильні приклади.
Технологія виявилася настільки вдалою, що її навіть вбудували в промислові сканери, які зчитували номери чеків у банках. Проте глобальної революції знову не відбулося. Для широкого кола складних задач нейромережі все ще програвали класичним математичним програмам. Даних в інтернеті було мало, комп’ютери працювали повільно, тому перші успіхи так і залишилися просто красивим анонсом майбутнього.
AlexNet: момент, коли світ змінився
Точкою зламу став 2012 рік. На той момент в індустрії вже з’явився ImageNet – гігантська віртуальна база, де вчені зібрали й вручну підписали понад 14 мільйонів фотографій усього підряд (від брелоків до собак). Щороку на цій базі проводився всесвітній чемпіонат з комп’ютерного зору. Програми з усього світу намагалися розпізнати, що зображено на фотографіях, але результати покращувалися дуже повільно. Індустрія вперлася в глухий кут, намагаючись вичавити максимум зі старих математичних формул.
Тоді на змагання заявилася невелика університетська команда: Алекс Кріжевський, Ілля Суцкевер та їхній керівник Джеффрі Гінтон. Суцкевер наполягав, що якщо дати нейромережі гігантську кількість даних, вона покаже магічний результат. Кріжевський написав унікальний код, який дозволяв тренувати нейромережу не на звичайному процесорі комп’ютера, а на потужних ігрових відеокартах (GPU), які вміють обробляти тисячі чисел одночасно. Свою переможну модель вони збирали й тренували буквально в спальні, на звичайному домашньому комп’ютері з двома відеокартами.
Їхня нейромережа, яку назвали AlexNet, була величезною для свого часу. Щоб вона не зійшла з розуму від такої кількості інформації і не почала просто тупо зазубрювати картинки, розробники пішли на хитрощі. Вони використали технологію dropout – під час навчання випадковим чином «вимикали» половину нейронів, змушуючи систему постійно шукати нові, більш надійні зв’язки та перестраховуватися. Також вони штучно розмножували фотографії: дзеркально відображали їх, обрізали краї та змінювали яскравість, щоб модель звикала до хаосу реального життя.
Результат чемпіонату приголомшив індустрію. Нейромережа AlexNet розгромила всі класичні програми з велетенським відривом, помиляючись майже вдвічі менше за найближчих конкурентів. Пояснити такий тріумф везінням чи випадковим збігом було неможливо. Провідні наукові журнали назвали це головним технологічним проривом десятиліття.
Саме з цієї точки весь світ припинив сперечатися, чи перспективні нейромережі. Індустрія зрозуміла: старий підхід помер. Тепер ми не пишемо код, який пояснює машині, як виглядає колесо чи шерсть тварини. Ми будуємо правильну структуру мережі, даємо їй купу відеокарт, мільярд картинок – і вона вчиться бачити самостійно.
Епоха глибини: VGG, Inception та ResNet
Після 2012 року технологію глибокого навчання почали розвивати шаленими темпами. Вчені зрозуміли, що чим більше шарів у нейромережі, тим краще вона розуміє складні концепції.
Невдовзі в Оксфорді створили модель VGG. Якщо в AlexNet було всього 8 шарів нейронів, то у VGG їхню кількість збільшили до 16-19. Архітектуру зробили максимально простою та послідовною, довівши, що сама по собі глибина мережі має колосальну силу.
Компанія Google пішла іншим шляхом із своєю моделлю GoogLeNet. Замість того щоб просто будувати довгу лінію з шарів, вони навчили мережу аналізувати картинку на різних рівнях масштабу одночасно всередині одного блоку. Це дозволило зробити систему вдвічі ефективнішою, використовуючи значно менше комп’ютерної пам’яті.
Але незабаром розробники зіштовхнулися з парадоксом: якщо робити мережі ще глибшими, вони раптом починали вчитися гірше, а точність падала. Через величезну кількість шарів математичні сигнали під час навчання просто «затухали» по дорозі.
Цю проблему вирішила архітектура ResNet у 2015 році. Вчені придумали геніальний трюк: вони дозволили сигналу перестрибувати через кілька шарів нейронів напряму. Якщо якийсь шар мережі виявлявся корисним – модель використовувала його, якщо ні – просто пропускала інформацію далі без втрат. Це дозволило побудувати гігантську нейромережу аж на 152 шари. Вона розпізнавала об’єкти на фотографіях краще за середньостатистичну людину. Штучний інтелект остаточно вийшов на промисловий рівень.
Ера Трансформерів: від розпізнавання картинок до ChatGPT
Коли нейромережі навчилися ідеально бачити фотографії, вчені вирішили перенести цей успіх на людську мову. Довгий час переклади та робота з текстом давалися машинам важко, бо алгоритми читали речення послідовно – слово за словом. Доходячи до кінця довгого абзацу, комп’ютер банально «забував», про що йшлося на початку.
Все змінилося у 2017 році, коли компанія Google опублікувала статтю з промовистою назвою «Увага – це все, що вам потрібно». Вони презентували нову архітектуру під назвою Transformer (Трансформер). Головна фішка цієї моделі – механізм штучної уваги (attention). Замість того щоб читати текст по порядку, Трансформер дивиться на все речення або навіть на весь текст одночасно. Він миттєво вираховує, як слова пов’язані між собою за змістом, незалежно від того, на якій відстані одне від одного вони стоять. Для мови це стало таким самим проривом, як ковзаючі вікна для картинок двадцять років тому.
Компанія OpenAI взяла цю технологію за основу і створила перші моделі серії GPT. Вони об’єднали дві речі: спочатку згодували нейромережі майже весь текстовий інтернет, щоб вона просто навчилася розуміти логіку мови та вгадувати наступне слово в реченні, а потім акуратно дотренували її під конкретні завдання. Масштаби зростали катастрофічно, і модель GPT-3 вже налічувала 175 мільярдів віртуальних контактів. Вона могла підтримувати діалог, писати програмний код чи створювати статті, просто зчитавши коротку інструкцію від користувача.
Коли у листопаді 2022 року з’явився знайомий усім ChatGPT, це не було якимось новим науковим відкриттям. Це була ідеальна продуктова збірка всього, що вчені розробляли роками. Модель просто навчили спілкуватися у форматі зручного чату і залучили тисячі людей-експертів, які оцінювали її відповіді (технологія RLHF), змушуючи систему бути ввічливою, зрозумілою та корисною. Сьогодні ці системи стали мультимодальними: остання версія GPT-5.5 – це вже єдиний цифровий організм, який одночасно і без затримок чує ваш голос, бачить картинку через камеру смартфона та миттєво відповідає текстом.
І ось тут коло замикається. Історія від першої розгромної перемоги нейромережі AlexNet над картинками до тріумфу ChatGPT над текстом – це одна й та сама лінія. Вона тримається на одному філософському принципі: не потрібно намагатися прописати для комп’ютера мільйон жорстких правил. Потрібно просто дати гнучкій нейромережі правильну структуру, колосальний обсяг даних і потужне залізо – і машина сама навчиться розуміти наш світ.