The first lines of code can tell more about a page than you think
Sometimes a page is written well enough: it answers the query, has clear headings, prices, terms, and a description of the service or product. But in search, it performs worse than expected. Or AI services barely use it when generating short answers to user queries.
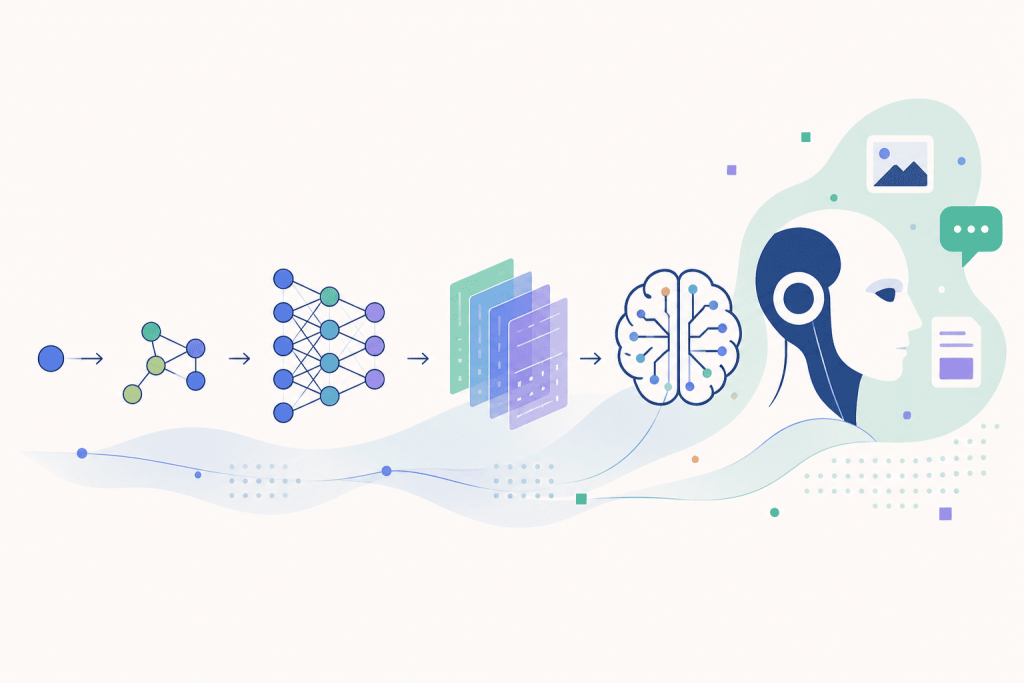
The evolution of ideas that led to modern artificial intelligence
Not so long ago, computers were completely blind. For a machine, any digital image was not a cat, a car, or a human face, but simply an endless table of pixel numbers. Teaching hardware to “see” the real world was considered an almost impossible task. The objects around us constantly change angle, lighting, scale, hide in shadows, or overlap with other things. The ordinary datasets of a few thousand photographs that scientists had were catastrophically insufficient to explain all this visual variety to a machine.
Artificial intelligence is changing everyday life and modern infrastructure
We didn’t even notice how artificial intelligence stopped being some futuristic toy. Now it’s just part of the software we use every day. When your email suggests how to finish a sentence for you or a service automatically removes noise from a voice recording, you are already inside an ecosystem of algorithms. It’s convenient. Many websites now generate product descriptions or news faster than a person can even open the page, and that frees up a huge amount of time for tasks that actually matter. AI has affected everything: from the way we search for information to the stock value of industry giants. This is no longer about chatbots, but about a new logic of how the digital world works, where routine gradually disappears.
Not so long ago, interacting with artificial intelligence felt like talking to a very diligent but inattentive assistant. Models handled short explanations or the translation of individual sentences fairly well, but they “fell apart” over longer distances. As soon as you added several extra conditions to a request or stretched out the dialogue, the logic got lost, and details were forgotten. The user had to spend more time editing the result than formulating the task itself.
Dependence on large amounts of memory is gradually decreasing
Until recently, running large language models was a process with a clear ceiling – the amount of available memory. If RAM was insufficient, the system would either refuse to start or run so slowly that it lost any practical meaning. This formed a persistent belief that the development of artificial intelligence depends solely on purchasing new batches of powerful GPUs. However, the engineering focus is now shifting toward algorithm efficiency rather than scaling up hardware.
Automation is changing the approach to infrastructure protection
Once, the physical security of a data center seemed straightforward and even linear: a solid door, a strict guard at the post, and a few cameras were enough. Back then, that was completely sufficient, because the facilities themselves were smaller, and their role was not as critical. Today, however, a data center is the “heart” of business and banking systems, so the approach to protection has changed. It is no longer enough to simply keep outsiders behind closed doors. It becomes important to see every corner of the site in real time, react instantly to the slightest deviations in equipment operation, and eliminate risks before they turn into a real incident.
Today discussions about artificial intelligence are gradually moving out of the “will it replace or will it not” debate into the sphere of practical task management. In practice we are not seeing mass disappearance of professions, but a redistribution of roles. AI becomes another tool in the stack, to which the technical part is delegated, while architectural oversight and responsibility for the final release remain with a human.
Universalization of tools as a new stage in the development of digital services
Just a few years ago, the digital lives of most people consisted of dozens of separate applications. Asana or Monday were used for task planning, GitLab for working with code, Wix for building websites, Duolingo for online learning, and specialized support platforms for working with clients. Each program performed a narrow function, and this was considered a normal model of computer use. Today, this logic is gradually changing. Artificial intelligence is taking over more and more tasks that previously required separate programs, and it does so within a single universal environment.
Transition from passive information processing to independent actions and decisions
Artificial intelligence has become a familiar tool for business and everyday life in recent years. Chatbots, text generation, recommendation systems, and analytics are no longer perceived as experimental technologies. At the same time, the concept of agentic artificial intelligence is increasingly appearing in professional discussions. It is often presented as the next stage in AI development, yet skepticism around this technology is also growing. Gartner analysts predict that more than 40% of agentic AI projects will be canceled by the end of 2027, indicating a serious gap between expectations and reality.
When digital systems begin to interact with the environment without human intervention
Until recently, artificial intelligence was perceived mainly as a software technology. It analyzed texts and images, helped with information search, or automated routine digital tasks. Today, however, AI is rapidly moving beyond screens and beginning to operate in the physical world. This shift became clearly visible after recent statements at technology exhibitions, where it was demonstrated that artificial intelligence is transitioning from a supporting tool to an active participant in real-world processes.